(本貼文所列出的程式碼,皆以 colab 筆記本方式執行,可由此下載)
現在我們要來看看 jax.numpy 執行起來比傳統的 Numpy 快多少?老頭分別做了以下 6 種試驗:
所使用的 Numpy 資料和 DeviceArray 資料如下:
shape = (10000, 10000)
# numpy data
np.random.seed(0)
x_np = np.random.normal(size=shape).astype(np.float32)
# jax data
key = jax.random.PRNGKey(0)
x_jax = jax.random.normal(key, shape, dtype=jnp.float32)
所用的計算則是 dot()。
np.dot()
jnp.dot()
這些試驗是在 colab 上執行,colab 分配給我的 CPU 及 GPU 型號分別是:
processor : 0 (or 1)
vendor_id : GenuineIntel
cpu family : 6
model : 79
model name : Intel(R) Xeon(R) CPU @ 2.20GHz
stepping : 0
microcode : 0x1
cpu MHz : 2199.998
cache size : 56320 KB
GPU 0: Tesla T4 (UUID: GPU-d515ed62-b83e-595b-a63d-1c11b56a2197)
最終的結果是這樣的:
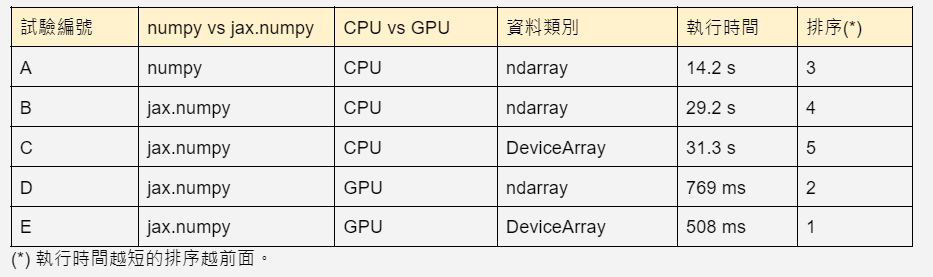
首先比較試驗編號 E 和 A,它們代表了最典型的 JAX 運算及 Numpy 運算,JAX 的執行速度足足比 numpy 快了 28 倍!效率的提升相當驚人。
另外,試驗編號 D 比編號 E 稍微多了一點時間,依據 JAX 文件的說法,這額外的時間是花在將 ndarray 轉成 DeviceArray 再移至 GPU 上面。
而從編號 B 和 C 的結果,我們可以了解到 jax.numpy 在純 CPU 的環境下,執行的效率比較不好,比典型的 Numpy 多了兩倍時間,這是老頭之前所沒有預料到的。未來得多做一些實驗來觀察 jax.numpy 在 CPU 下的表現。
接下來分別說明這些實驗的執行過程。
首先我們要把 colab 執行環境切到 CPU only,以執行實驗 A,B 和 C:
編輯 → 筆記本設定 → 硬體加速器 : 選取 None
選好後記得按「儲存」
把該有的程式庫 import 進來:
import jax
import jax.numpy as jnp
import numpy as np
宣告 10000 x 10000 的亂數矩陣:
shape = (10000, 10000)
# numpy data
np.random.seed(0)
x_np = np.random.normal(size=shape).astype(np.float32)
# jax data
key = jax.random.PRNGKey(0)
x_jax = jax.random.normal(key, shape, dtype=jnp.float32)
可以執行測試了:
# test A
%timeit np.dot(x_np, x_np.T)
# test B
%timeit jnp.dot(x_np, x_np.T).block_until_ready()
# test C
%timeit jnp.dot(x_jax, x_jax.T).block_until_ready()
眼尖的讀者可能發覺在執行 jax.numpy API dot() 時,老頭附帶了 “block_until_ready()”,原因是 JAX 使用了「asynchronous dispatch」[8.1],在執行 dot() 等 JAX 運算時,JAX 會非同步的執行運算,而儘早的將控制權交還給 Python,並這會造成 %timeit 所得到的時間太短,而不能顯示出 dot 運算真正的執行時間。“block_until_ready()” 即是告訴 JAX,等計算結果出來後,才釋出控制權。這樣, %timeit 所得到的時間才是我們要的。
其次我們要在 colab 上把執行環境切回到使用 GPU 做為硬體加速器,再來做實驗 D 和 E:
編輯 → 筆記本設定 → 硬體加速器 : 選取 GPU
選好後記得按「儲存」
程式庫的 import 和宣告亂數矩陣,和 On CPU 完全相同。
執行另外兩個測試:
# test D
%timeit jnp.dot(x_np, x_np.T).block_until_ready()
# test E
%timeit jnp.dot(x_jax, x_jax.T).block_until_ready()
讀者可以在老頭提供的 colab 筆記本上,自己做一下實驗,看看你自己做出來的結果如何。
註:
[8.1] 有關 asynchronous dispatch,可參考 JAX 文件 Asynchronous dispatch 。